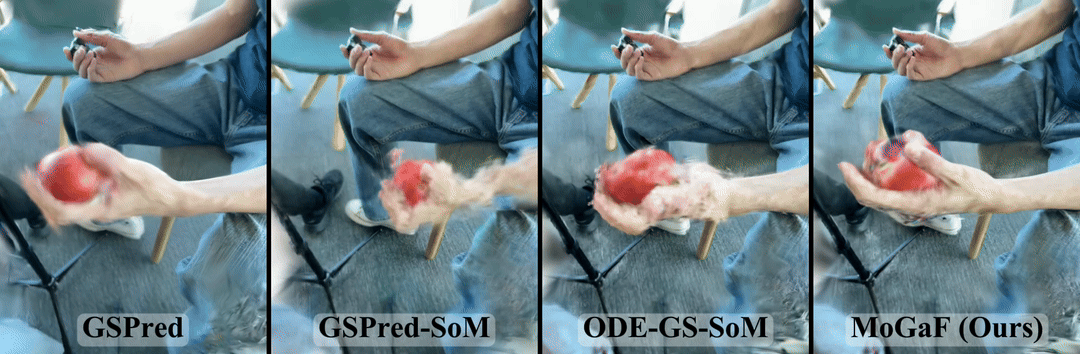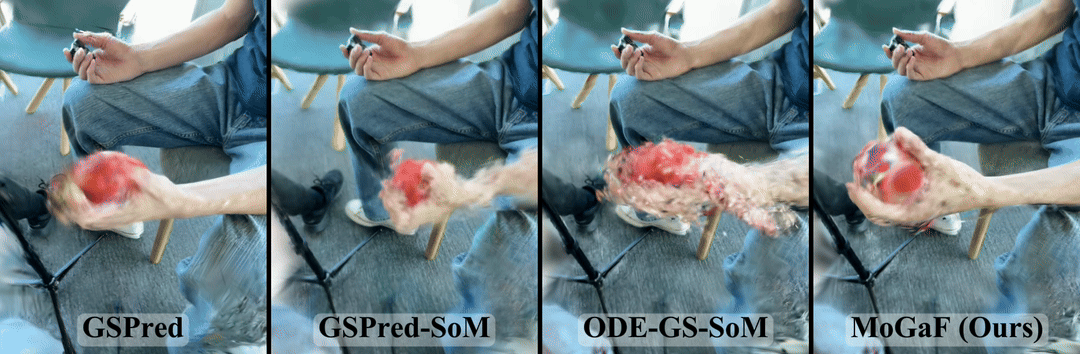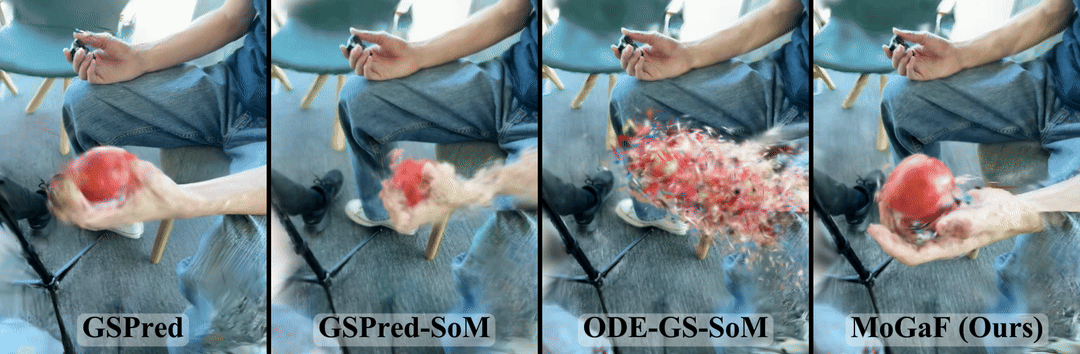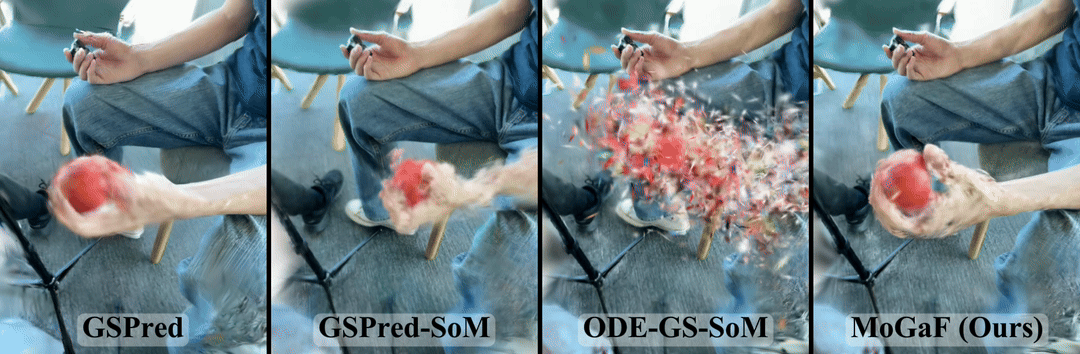
Method Overview
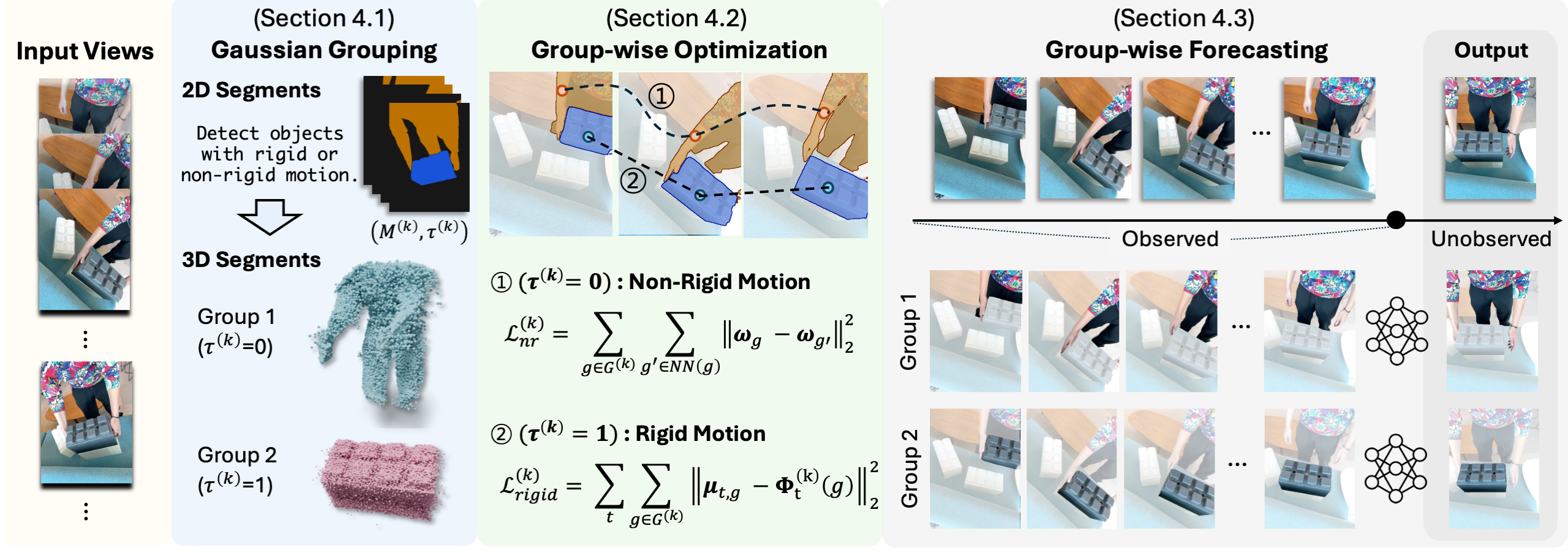
MoGaF forecasts future dynamic scenes by explicitly structuring the 4D Gaussian space into motion-consistent units before extrapolation. Instead of treating each Gaussian independently, our pipeline first discovers object-level motion groups, then enforces group-level geometric constraints, and finally predicts future trajectories in that structured motion space.
- Motion-aware Gaussian Grouping. Starting from optimized 4D Gaussians, MoGaF groups primitives into object-level motion units and assigns each group as rigid or non-rigid. The grouping alternates keyframe seeding and feature-space region growing for robust grouping under occlusion and fast motion.
- Group-wise Motion Optimization. For rigid groups, MoGaF enforces a shared SE(3) motion with rigid anchoring. For non-rigid groups, it applies local motion smoothness over neighboring Gaussians. This reduces per-Gaussian drift and improves temporal coherence.
- Group-wise Future Forecasting. MoGaF trains a lightweight transformer forecaster per motion group to extrapolate future Gaussian trajectories. With masked motion modeling during training, the model remains stable over longer forecasting horizons.